(1) Optimization of SMF Obectives (Bouchard-Cote, Jordan)
This paper discusses the Structured Mean Field (SMF) approach for inference in graphical models. We have covered SMF in Section 5.5 of Wainwright-Jordan. We also looked at Naive Mean Field (NMF) in Wainwright-Jordan (Section 5.3). Recall that in Mean Field methods, we break a graphical model into “tractable” subgraph(s) and then do approximate inference based on the subgraph(s) and its properties. In NMF, the subgraph is basically the graph with no edges. In SMF, some edges are considered while still keeping the subgraph tractable. The main objective in this paper is to look at tractability of the SMF method (which depends on the choice of the subgraph). Interestingly, some graph properties of the chosen subgraph(s) determine the tractability of the SMF method.
Specifically, if a subgraph is v-acyclic, then the computation can be done in quick time. If the subgraph is b-acyclic, then the computation is much more complicated. A v-acyclic subgraph is one in which adding any single edge from the original graph results in an acyclic subgraph ( Hence the name very-acyclic). If adding any edge from the graph to the tractable subgraph results in a cyclic graph, then the subgraph is b-acyclic (barely-acyclic).
Points to consider are:
Sections 2.1 and 2.2 cover the basics, which we know know from Wainwright-Jordan. The only addition is second part of Eq 3. Hessian of the log partition function is the Variance of the Sufficient statistics.
Section 2.3 is also mostly covered in Wainwright-Jordan, except the part from the last paragraph in Column 1. Here Γ maps to the “missing potential” expectations. This is to show that the optimization can be done in the smaller space of tractable potentials, while ignoring the “missing potentials”.
(a) Think about the dimension of the space in which τ, f , and θ exist.
Section 2.4 gives the formula for Mean Field updates (top of page 4). Remember τ are the mean parameters in the tractable subfamily. The formula involves a term J which is defined in Definition 2.
Section 3.1 explains what v-acyclic and b-acyclic mean. We will talk about it very briefly.
Section 3.2 shows how the Mean Field update formula can be further broken down into multiple subgraphs (connected components). It is these subgraphs and their properties that determine the complexity of the update equation.
Section 3.3 shows that the updates are easy to compute if the subgraph (connected component) is v-acyclic (Shown by considering three subcases). Note that 1[f=(a,s)] is an indicator function.
(b) What does g = (e, (s,t)) mean?
(c) It is important to see why equation in Proposition 5 does not depend on

Section 3.4 shows how the update equations are equivalent to Gibbs sampling. We will talk about this.
(d) Hopefully students with experience in Gibbs sampling can help the rest make the connection.
Section 3.5 shows how the update equation is not as easy to solve in case of b-acyclic subgraphs.
(e) This is probably the most confusing part of this paper, we will probably spend good amount of time going through this section.
Results
(f) Choosing a b-acyclic subgraph for SMF in a given graphical model, we can achieve much better accuracy (Figure 3)
(g) Convergence time : v-acyclic SMF takes an order magnitude more time compared to NMF. b-acyclic SMF takes two orders of magnitude more time than v-acyclic SMF (Figure 4) – as expected from the theory in Section 3.
(2) EP for Generative Aspect Model (Minka, Lafferty)
This paper talks about use of EP for a Generative Aspect model (which is the same as an LDA model (?)). It is thus related to Section 6 of Wainwright-Jordan paper. This paper makes a comparison between Variational Inference (VB) and Expectation Propagation (EP). Results show EP is more accurate than VB.
The main objective for the discussion is to understand how model parameters are Learned for exponential families. We will be looking at Section 5 of the paper mainly. But section 5 is a small section and understanding section 4 will help go through 5 more meaningfully. Section 4 was covered in last fortnight’s meeting. But since it is important, we will brush up on the main points from last fortnight’s meeting.
We will briefly go over the model itself (Section 2). We should not be spending too much time on this section during the meeting. Section 3 discusses EP for the GA model. Again, we will quickly review this because it was done earlier. We should now be able to relate the “inclusion-deletion” being talked about this section to the EP algorithm as explained in Section 4 (Figure 4.7)
Section 5 will be the main discussion point.
(a) Why not use EM algorithm in a straight-forward manner ( Treating λ as a hidden variable ) This point is mentioned briefly after Eq 26. We should understand Why this is so.
Section 5.1 gives the one possible learning algorithm, which can be used for VB approach. Points to think about:
(b) How can Eqs 27 and 28 be understood as EM? This point is mentioned in paragraph 2 of section 5.1
(c) Why the same approach cannot be used for EP? Last few lines of section 5.1
Section 5.2 gives the learning algorithm for EP approach (Can be used for VB too (?)).
(d) How is Eq 29 the log likelihood in this model?
(e) We should understand what Eqs 31 – 34 mean. It might be helpful to revisit section 4.2 to understand what each of the RHS quantities mean.
Results show that EP does significantly better than VB. Points:
(f) For synthetic data, EP likelihood resembles the exact likelihood. VB likelihood resembles the max likelihood (Figure 1). (Briefly, we will talk about what exact and max likelihoods are)
(g) For real data, EP has lower “perplexity” than VB (Figure 3). (Briefly, what is “perplexity”?)

Regarding 3.4:
In ordinary gibbs sampling, you sample one variable conditioned on the values assigned to all the other variables. This is similar to naive mean field. In blocked gibbs sampling, you sample a set of variables conditioned on the values assigned to all other variables outside the set. For instance, in a Restricted Boltzmann Machine, you can sample all the variables in one layer conditioned on the values of the variables in the other layer, since variables in a layer are conditionally independent given the other layer. This is similar to structured mean field with a v-acyclic subgraph.
That said, I believe there is a typo at the top left of page 6 in the definition of the matrix B. I think the final indicator function should be![1[X_b (t-1) = t']](https://s0.wp.com/latex.php?latex=1%5BX_b+%28t-1%29+%3D+t%27%5D&bg=ffffff&fg=000000&s=0&c=20201002) . It’s a bit confusing because the
. It’s a bit confusing because the  in
in 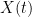 refers to the time step of the gibbs sampler, whereas the second
refers to the time step of the gibbs sampler, whereas the second  refers to the edge (a,b) having the value (s,t), as in case 1 in section 3.3.
refers to the edge (a,b) having the value (s,t), as in case 1 in section 3.3.
Comment by Gary — July 21, 2009 @ 12:58 pm |
Regarding 3.5:
There’s a typo at the bottom left of page 6, in the first probability, the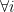 should start from 0, not 1.
should start from 0, not 1.
I’m less certain of this, but I believe there is also a typo in the definition of![\theta^{[g]}_h](https://s0.wp.com/latex.php?latex=%5Ctheta%5E%7B%5Bg%5D%7D_h&bg=ffffff&fg=000000&s=0&c=20201002) on page 7, and that the first case should be when
on page 7, and that the first case should be when  and not
and not 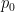 . Also, to be clear,
. Also, to be clear,  should be over all interior edges of
should be over all interior edges of  , excluding the endpoints
, excluding the endpoints  and
and  .
.
On the other hand, I think there’s the opposite typo in the equation of Proposition 6 on page 7, in that the second case should be when and not
and not  .
.
Comment by Gary — July 21, 2009 @ 2:15 pm |